Dapper
Motivation
在分散式環境下,Google的業務每個request可能會需要數十、數百甚至上千個其他服務來一同完成,需要有方式來知道一個request被完成的過程中,紀錄每個service花了多少時間、甚至留下application log來知道執行細節。
Goals
- 不影響service performance (latency、throughput)
- 對service 來說是transparent。
Data structure
trace tree
每個request 會產生一個trace tree,每個tree有一個trace id,每個node是一個span,span可以有child span。
span
span 裡面會紀錄service 收到request到處理完成的時間。每個span 有自己的span id,如果有需要,也可以產生child span,例如進行另外的rpc 呼叫,就會把trace id、自己的span id等資訊帶到下一個service。
Architecture
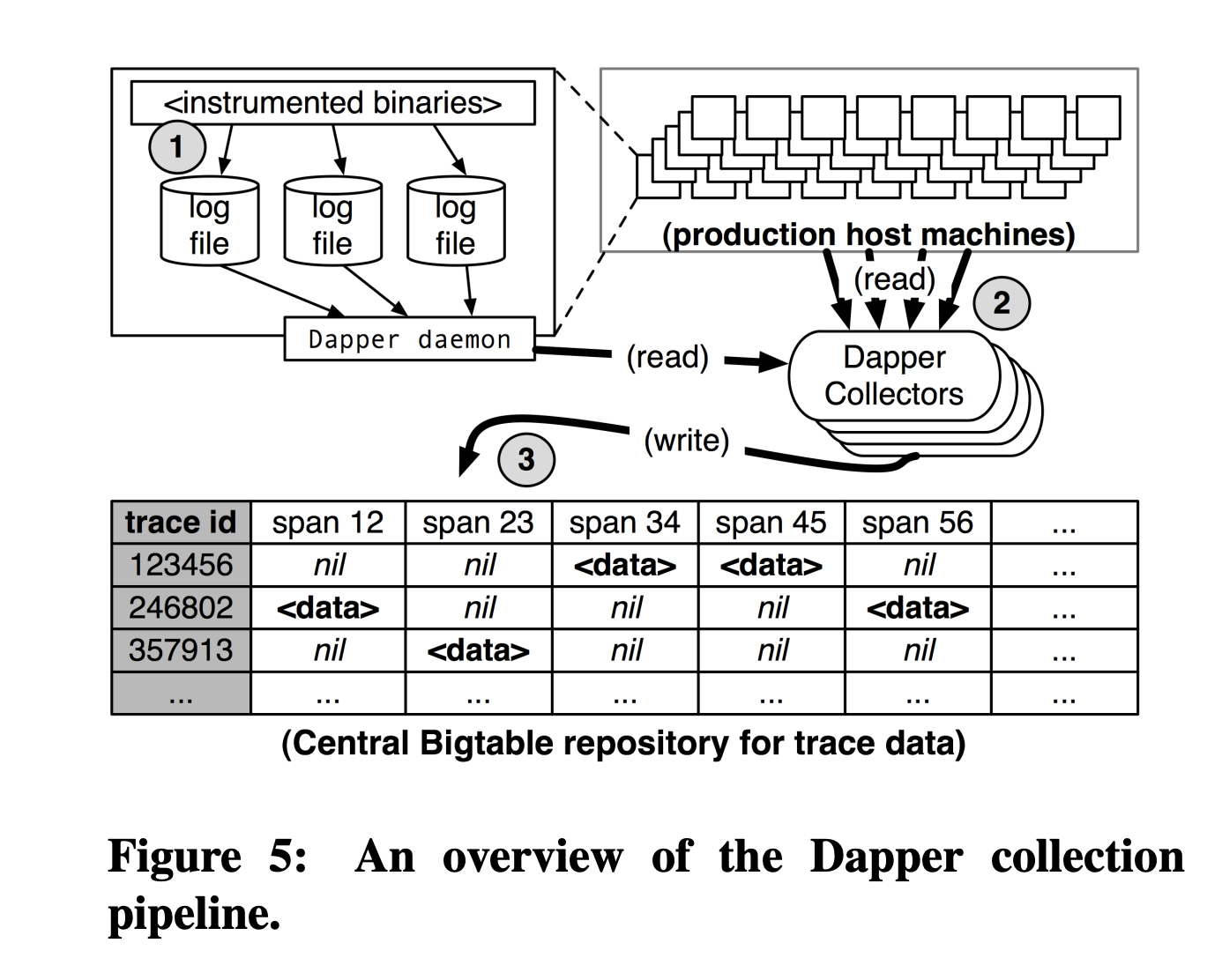
log file
被改寫過的SDK或dependency binaries會把資料寫到log file。
Dapper daemon & collectors
Dapper daemon 或 collectors會pull 這些log來處理。
Bigtable
這些資料最後會被存到Dapper的資料庫,也就是Bigtable。
Implementation
Instrumentation points
因為Google的service太多了,不想要每個service都要增加dependency�,所以Dapper被實作在常用的libraries,例如thread local context、RPC SDK等等,trace和span邏輯對service owner 來說是tranparent。
Annotations
其實就是log。有時候光從Dapper自動蒐集到的metric無法得到足夠的資訊,service owner還是可以選擇include Dapper API,把 application log也送到後台。
Sampling
Google的service實在太多,如果每個request都搜集的話會把Dapper後端打爆,而且這些request I/O也會對service performance產生影響,所以Dapper daemon會做sampling,以Google的scale,即使取樣1/1024也不影響monitoring和debugging。
Visualization
有一個web app會把trace tree做visualzation,將蒐集到的資料視覺化,可以幫助developer更快的定位問題。